In almost every conversation I have had regarding overcoming the issue that latency causes in global application delivery, I have been met with cynicism and outright disbelief that there is a solution for such a problem. Yet, by the end of each conversation, the opposite is true.
To understand the answer to the ever-growing latency problem for global companies as a result of centralising applications into global cloud infrastructures, to be accessed by remote branches around the world, the problem needs to be examined first.
The problem in itself is technically complex, which is why I have introduced a way to communicate it to the business side of the organisation, in a non-technical manner.
Global application delivery and performance has been an issue for many years, but is a relatively new and growing problem for specific regions. I will use South African companies to illustrate this.
Going to extremes
Most South African companies still consume their business applications from inside the network or a local cloud provider. South African application users will probably note that when they access their company application in HQ, it's faster than when they access it from a regional office. There is no doubt the role of bandwidth comes into play, but there is another problem that is far greater and which they will only become aware of in more extreme scenarios of application delivery. This is the problem of latency.
Latency represents the time it takes to send data (in this case an application) between one point and another (the application and the user). Ideally, the lowest latency is always sought. But, not many people really understand what the effect of introducing more and more latency between these two points is, until now. As companies move their business applications from SA to global locations such as Azure, 365, AWS, etc (over the Internet or private network), they are noticing a significant and detrimental effect on user experience. And throwing bandwidth at this international problem is unaffordable and mostly futile. That's because the issue is actually to do with latency.
Global application delivery and performance has been an issue for many years, but is a relatively new and growing problem for specific regions.
It's quite simple to explain. The problem is in the TCP protocol. This protocol is responsible for supporting the transportation of the application from the user to the server. If the latency is low, the TCP protocol determines a large session or window size for the transmission, calculating window size in relation to latency. This translates into lots of bandwidth for a user. But, if the latency is higher, it determines a smaller window size or session, which reduces the amount of bandwidth for the user. The more latency, the worse the user experience.
Here is an illustration:
In the graph below, there is a 100Mbps (megabits per second) network link used to access the application. Assume there is only one user on that link to remove general congestion. When the latency is 1ms, the user session (TCP window size) will be roughly 97Mbps, which is evident on the far left-hand side of the graph. SA's cloud services are generally within 20ms of users, and therefore perform well.
But, what may be noticed as more latency is introduced between the user and the application is that the window size reduces, as indicated in the movement from left to right on the graph. Considering most globally situated applications are accessed in excess of 200ms, available bandwidth as a user will reduce to only a few Mbps or even Kbps. This has nothing to do with the provider, but is simply based on the way TCP calculates the session and TCP window sizes based on latency.
It's also important to understand that when TCP IP transmits data, it does so by breaking down the data or message into many smaller packets. It sends a few packets between the user and application (or two points), and then waits for a response (or receipt) from the destination before sending more. Each time this receipt takes 200ms to be received, and each time the TCP protocol then uses that information to calculate the session or window size (handshake and buffering).
Diagram 1.1 TCP IP latency problem
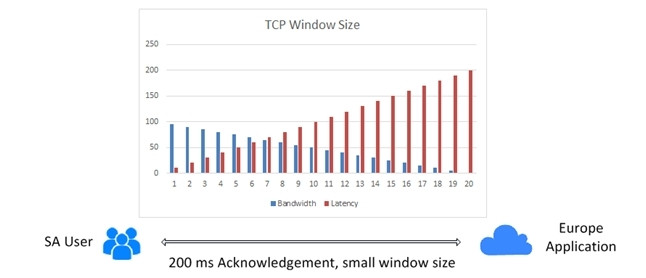
Most people would believe that because latency is based on the physical properties of the network, in this case, a fibre cable system between SA and Europe, it is not possible to resolve this issue, as it is physically impossible to reduce the latency. In that determination, they are correct. But, the problem is not actually about the latency; the problem is about how TCP calculates session sizes using latency.
Solving latency in global app delivery
Now, with a better view of the problem, I can explain how to resolve it using technology. This is known and marketed as TCP IP acceleration.
The solution to high latency networks and application performance is actually as simple as the problem itself. If users want to improve the session and window size over a high latency network, they need to implement a mechanism that provides the TCP protocol with an acknowledgement or receipt, without having to travel all the way to the destination (200ms).
The diagram below (1.2) illustrates that by passing the TCP session through localised technology, users can provide a local receipt to the TCP protocol in less than 5ms. The result of this change is the TCP protocol uses the faster receipt to determine a far larger window size, which has a direct translation to session size and user experience (perceived latency of less than 10ms).
This requires a company to place optimisation technology on its network between these locations, or to leverage a network that has built this capability into its local POPs. In this case, its POP in the UK and its POP in SA would have TCP optimisation.
Diagram 1.2 Solving TCP latency problem
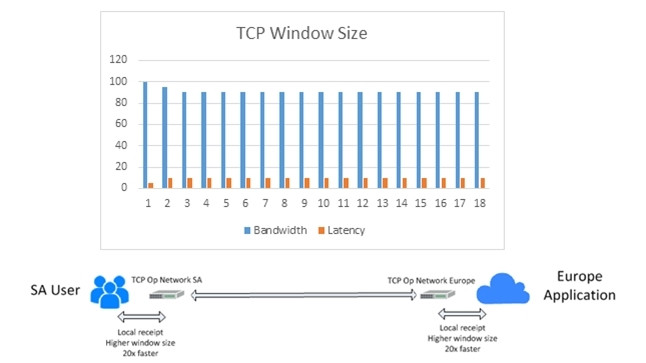
TCP IP acceleration is a critical consideration for customers leveraging SaaS, IaaS or PaaS on a global level. Some of these technologies are also accompanied by compression, caching and de-duplication to further enhance the user experience and cost of international bandwidth.
The alternative to these options is to keep applications in a local cloud network in-country, which is challenging for global companies that have a centralised application strategy.
Share