Fujitsu Laboratories and Hokkaido University today announced the development of a new technology based on the principle of “explainable AI” that automatically presents users with steps needed to achieve a desired outcome based on AI results about data, for example, from medical checkups.
“Explainable AI” represents an area of increasing interest in the field of artificial intelligence and machine learning. While AI technologies can automatically make decisions from data, “explainable AI” also provides individual reasons for these decisions – this helps avoid the so-called “black box” phenomenon in which AI reaches conclusions through unclear and potentially problematic means.
While certain techniques can also provide hypothetical improvements one could take when an undesirable outcome occurs for individual items, these do not provide any concrete steps to improve.
For example, if an AI that makes judgments about the subject’s health status determines that a person is unhealthy, the new technology can be applied to first explain the reason for the outcome from health examination data like height, weight and blood pressure. Then the new technology can additionally offer the user targeted suggestions about the best way to become healthy, identifying the interaction among a large number of complicated medical checkup items from past data, and showing specific steps to improvement that take into account feasibility and difficulty of implementation.
Ultimately, this new technology offers the potential to improve the transparency and reliability of decisions made by AI, allowing more people in the future to interact with technologies that utilise AI with a sense of trust and peace of mind. Further details will be presented at the AAAI-21, Thirty-Fifth AAAI Conference on Artificial Intelligence opening from Tuesday, 2 February.
Developmental background
Currently, deep learning technologies widely used in AI systems requiring advanced tasks such as face recognition and automatic driving automatically make various decisions based on a large amount of data using a kind of black box predictive model. In the future, however, ensuring the transparency and reliability of AI systems will become an important issue for AI to make important decisions and proposals for society. This need has led to increased interest and research into "explainable AI" technologies.
For example, in medical checkups, AI can successfully determine the level of risk of illness based on data like weight and muscle mass (Figure 1 (A)). In addition to the results of the judgment on the level of risk, attention has been increasingly focused on "explainable AI" that presents the attributes (Figure 1 (B)) that served as the basis for the judgment.
Because AI determines that health risks are high based on the attributes of the input data, it’s possible to change the values of these attributes to get the desired results of low health risks.
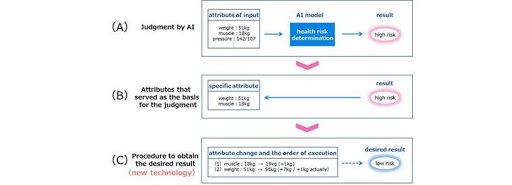
Issues
In order to achieve the desired results in AI automated decisions, it is necessary not only to present the attributes that need to be changed, but also to present the attributes that can be changed with as little effort as is practical.
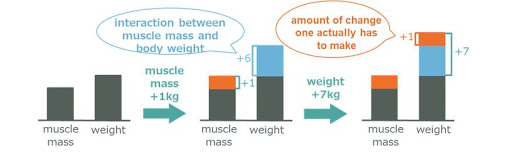
In the case of medical checkups, if one wants to change the outcome of the AI’s decision from high risk status to low risk status, achieving it with less effort may seem to increase muscle mass (Figure 2 Change 1) – but it is unrealistic to increase one’s muscle mass alone without changing one’s weight, so actually increasing weight and muscle mass simultaneously is a more realistic solution (Figure 2 Change 2). In addition, there are many interactions between attributes such as weight and muscle mass, such as causal relationships in which weight increases with muscle growth, and the total effort required to make changes depends on the order in which the attributes are changed. Therefore, it is necessary to present the appropriate order in which the attributes are changed. In Figure 2, it is not obvious whether weight or muscle mass should be changed first in order to reach Change 2 from the current state, so it remains challenging to find an appropriate method of change taking into the account the possibility and order of changes from among a large number potential candidates.

About the newly developed technology
Through joint research on machine learning and data mining, Fujitsu Laboratories and Arimura Laboratory at the Graduate School of Information Science and Technology, Hokkaido University have developed new AI technologies that can explain the reasons for AI decisions to users, leading to the discovery of useful, actionable knowledge.
AI technologies such as LIME [1] and SHAP [2], which have been developed as AI technologies to support decision-making of human users, are technologies that make the decision convincing by explaining why AI made such a decision. The jointly developed new technology is based on the concept of counterfactual explanation [3] and presents the action in attribute change and the order of execution as a procedure. While avoiding unrealistic changes through the analysis of past cases, the AI estimates the effects of attribute value changes on other attribute values, such as causality, and calculates the amount that the user actually has to change based on this, enabling the presentation of actions that will achieve optimal results in the proper order and with the least effort.
For example, if one has to add 1kg of muscle mass and 7kg to their body weight in order to reduce the risk in the input attribute and its order (Figure 1 (C)) that they change to obtain the desired result in a medical checkup, it’s possible to estimate the relationship by analysing the interaction between the muscle mass and the body weight in advance. That means that if one adds 1kg of muscle mass, the body weight will increase by 6kg. In this case, out of the additional 7kg required for weight change, the amount of change required after the muscle mass change is just 1kg. In other words, the amount of change one actually has to make is to add 1kg of muscle mass and 1kg of weight, so one can get the desired result with less effort than the order changing their weight first.
Effects
Using the jointly developed counterfactual explanation AI technology, Fujitsu and Hokkaido University verified three types of data sets [4] that are used in the following use cases: diabetes, loan credit screening, and wine evaluation. By combining three key algorithms for machine learning – Logistic Regression [5], Random Forest [6] and Multi-Layer Perceptron [7] – with the newly developed techniques, we have verified that it becomes possible to identify the appropriate actions and sequence to change the prediction to a desired result with less effort than the effort of actions derived by existing technologies in all datasets and machine learning algorithm combinations. This proved especially effective for the loan credit screening use case, making it possible to change the prediction to the preferred result with less than half the effort.
Using this technology, when an undesirable result is expected in the automatic judgment by AI, the actions required to change the result to a more desirable one can be presented. This will allow for the application of AI to be expanded not only to judgment but also to support improvements in human behaviour.
Future plans
Going forward, Fujitsu Laboratories will continue to combine this technology with individual cause-and-effect discovery technologies [8] to enable more appropriate actions to be presented. Fujitsu will also use this technology to expand its action extraction technology [9] based on its proprietary "FUJITSU AI Technology Wide Learning", with the aim of commercialising it in fiscal 2021.
Hokkaido University aims to establish AI technology to extract knowledge and information useful for human decision-making from various field data, not limited to the presentation of actions.
[1] LIME: An explainable AI technology. Explains in a simple, interpretable model.
[2] SHAP: An explainable AI technology. Explains by showing the contribution of the explanatory variable in the model.
[3] Counterfactual explanation: A method of indicating and explaining a state that is different from the truth, such as: "If I had done this, the result would have been."
[4] Data sets: The UC Irvine Machine Learning Repository is a world-famous repository that provides a number of data sets for comparative evaluation of machine learning, and FICO, a credit scoring company, published data for machine learning in three types of data sets: diabetes, loan credit screening, and wine evaluation.
[5] Logistic regression: A type of machine learning algorithm. A probability model that combines a logistic function with a hyperplane.
[6] Random forest: A type of machine learning algorithm. A prediction model that makes stable decisions by using a large number of decision tree classifiers.
[7] Multi-layer perceptron: A type of machine learning algorithm. A model for training multiple neural networks.
[8] Individual cause-and-effect discovery technologies: Fujitsu Develops Technology to Discover Characteristic Causal Relationships of Individual Data in Medicine, Marketing, and More (2020/12/17)
[9] "FUJITSU AI Technology Wide Learning" action extraction technology: Fujitsu Bolsters its AI "Wide Learning" Technology with New Technique to Deliver Optimized Action Plans in Various Fields (2019/9/13)
Share
Fujitsu
Fujitsu is the leading Japanese information and communication technology (ICT) company offering a full range of technology products, solutions and services. Approximately 130,000 Fujitsu people support customers in more than 100 countries. We use our experience and the power of ICT to shape the future of society with our customers. Fujitsu Limited (TSE:6702) reported consolidated revenues of 3.9 trillion yen (US$35 billion) for the fiscal year ended March 31, 2020. For more information, please see www.fujitsu.com.
Fujitsu Laboratories Ltd.
Founded in 1968 as a wholly owned subsidiary of Fujitsu Limited, Fujitsu Laboratories Ltd. is one of the premier research centers in the world. With a global network of laboratories in Japan, China, the United States and Europe, the organization conducts a wide range of basic and applied research in the areas of Next-generation Services, Computer Servers, Networks, Electronic Devices and Advanced Materials. For more information, please see: http://www.fujitsu.com/jp/group/labs/en/.
Editorial contacts